Treinamento Inicial
treinamento_inicial.RmdObjetivo do Treinamento
Este treinamento busca fazer uma introdução ao uso do pacote epe4md, percorrendo todas as funções do pacote e apresentando como o usuário pode alterar parâmetro e premissas do modelo. Este treinamento não explora a construção, ou “o que está por trás” de cada função.
O pacote epe4md
O objetivo principal do pacote epe4md é realizar projeções do mercado de Micro e Minigeração Distribuída no Brasil. O modelo 4MD traz resultados de número de adotantes, capacidade instalada, geração de energia e montante de investimentos.
Página no github: https://github.com/EPE-GOV-BR/epe4md
Instalação
devtools::install_github("EPE-GOV-BR/epe4md")Observação: você precisa ter instalado o pacote “devtools” anteriormente. Caso ainda não tenha feito, instale através do seguinte código.
install.packages("devtools")A licença
A licença do pacote pode ser verificada com o seguinte código
packageDescription("epe4md", fields = "License")
#> [1] "GPL (>= 3)"A licença GPL v3 significa que programa é um software livre, podendo ser distribuído e modificado. No entanto, qualquer modificação do código original precisa ser lançada com a mesma licença GPL v3. Veja mais detalhes no seguinte link: https://github.com/EPE-GOV-BR/epe4md/blob/main/LICENSE.md
Acessando as vinhetas (tutoriais)
O site do pacote possui artigos com tutoriais (inclusive este). Acesse através do seguinte link: EPE’s 4MD model to forecast the adoption of Distributed Generation • epe4md (epe-gov-br.github.io)
Rodando a primeira projeção
library(tidyverse)
#> Warning: package 'tidyverse' was built under R version 4.4.3
#> Warning: package 'ggplot2' was built under R version 4.4.3
#> Warning: package 'tibble' was built under R version 4.4.3
#> Warning: package 'tidyr' was built under R version 4.4.3
#> Warning: package 'readr' was built under R version 4.4.3
#> Warning: package 'purrr' was built under R version 4.4.3
#> Warning: package 'dplyr' was built under R version 4.4.3
#> Warning: package 'stringr' was built under R version 4.4.3
#> Warning: package 'forcats' was built under R version 4.4.3
#> Warning: package 'lubridate' was built under R version 4.4.3
library(epe4md)A função epe4md_calcula condensa todas as funções intermediárias e permite gerar resultados a partir da execução de apenas essa função. No entanto, é preciso inicialmente definir o ano base da projeção e as premissas regulatórias (ver explicação no help da função ou no seguinte tutorial: https://epe-gov-br.github.io/epe4md/articles/fazendo_projecoes.html
premissas_regulatorias <- readxl::read_xlsx(system.file("dados_premissas/2024/premissas_reg.xlsx", package = "epe4md"))
resultado <- epe4md_calcula(
ano_base = 2024,
premissas_reg = premissas_regulatorias,
ano_max_resultado = 2028)
#> Registered S3 method overwritten by 'tsibble':
#> method from
#> as_tibble.grouped_df dplyrA partir dessa planilha de resultados, você pode explorar resultados por UF, fonte, segmento, entre outros. Isso é feito com o auxílio de funções da coleção tidyverse.
resumo_rj <- resultado %>%
filter(uf == "RJ") %>%
group_by(segmento, ano) %>%
summarise(adotantes_ano = sum(adotantes_mes),
capacidade_ano_mw = sum(pot_mes_mw)) %>%
ungroup()Ou pode utilizar a seguinte função do pacote epe4md para um resumo nacional.
resumo_br <- epe4md_sumariza_resultados(resultado)Também pode gerar uma série de gráficos com funções do pacote.
Veja o “Help” do Rstudio para mais detalhes das funções
epe4md_graf_pot_acum(resultado)
epe4md_graf_pot_segmento(resultado)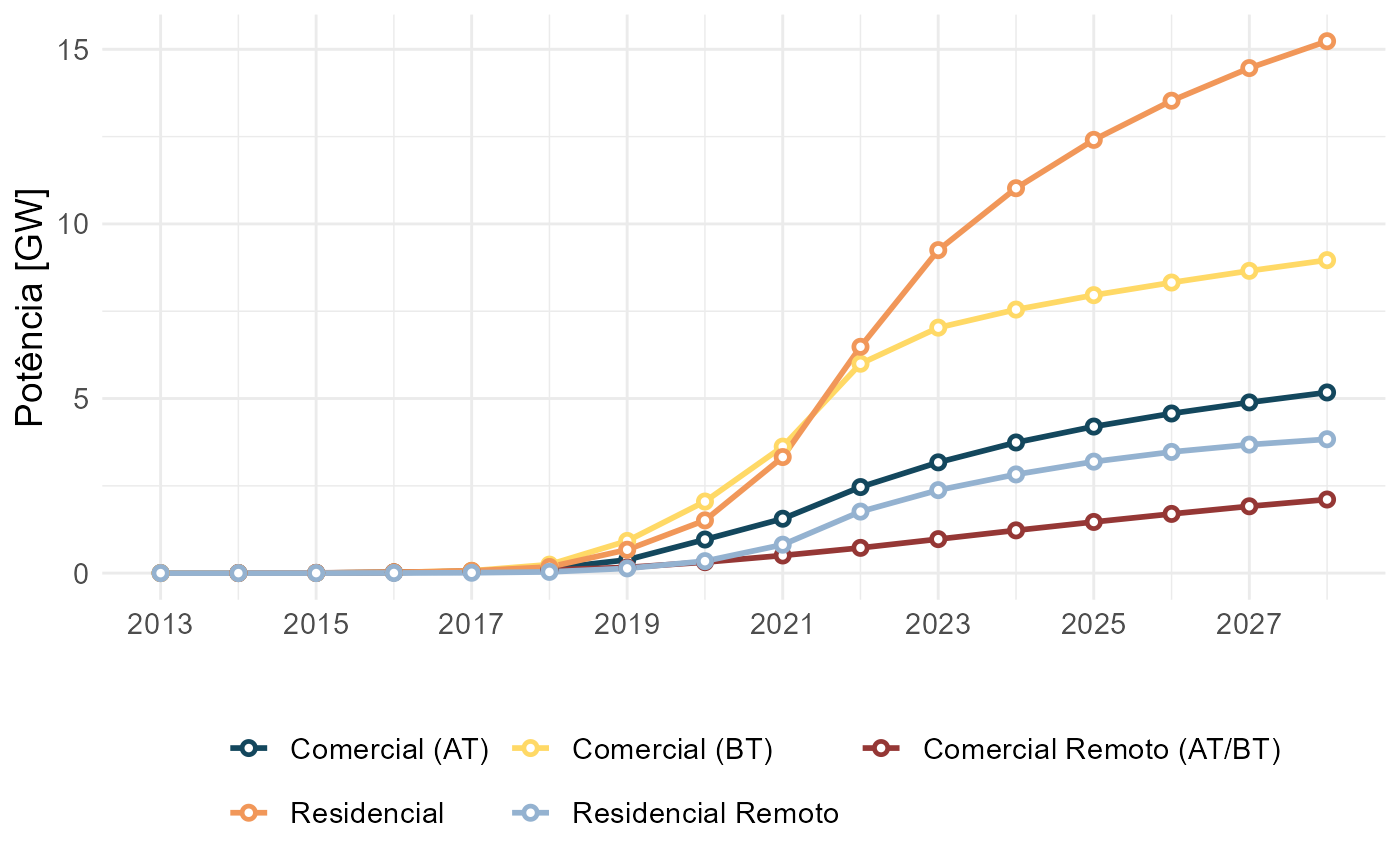
epe4md_graf_geracao_mes(resultado, cor = "darkblue")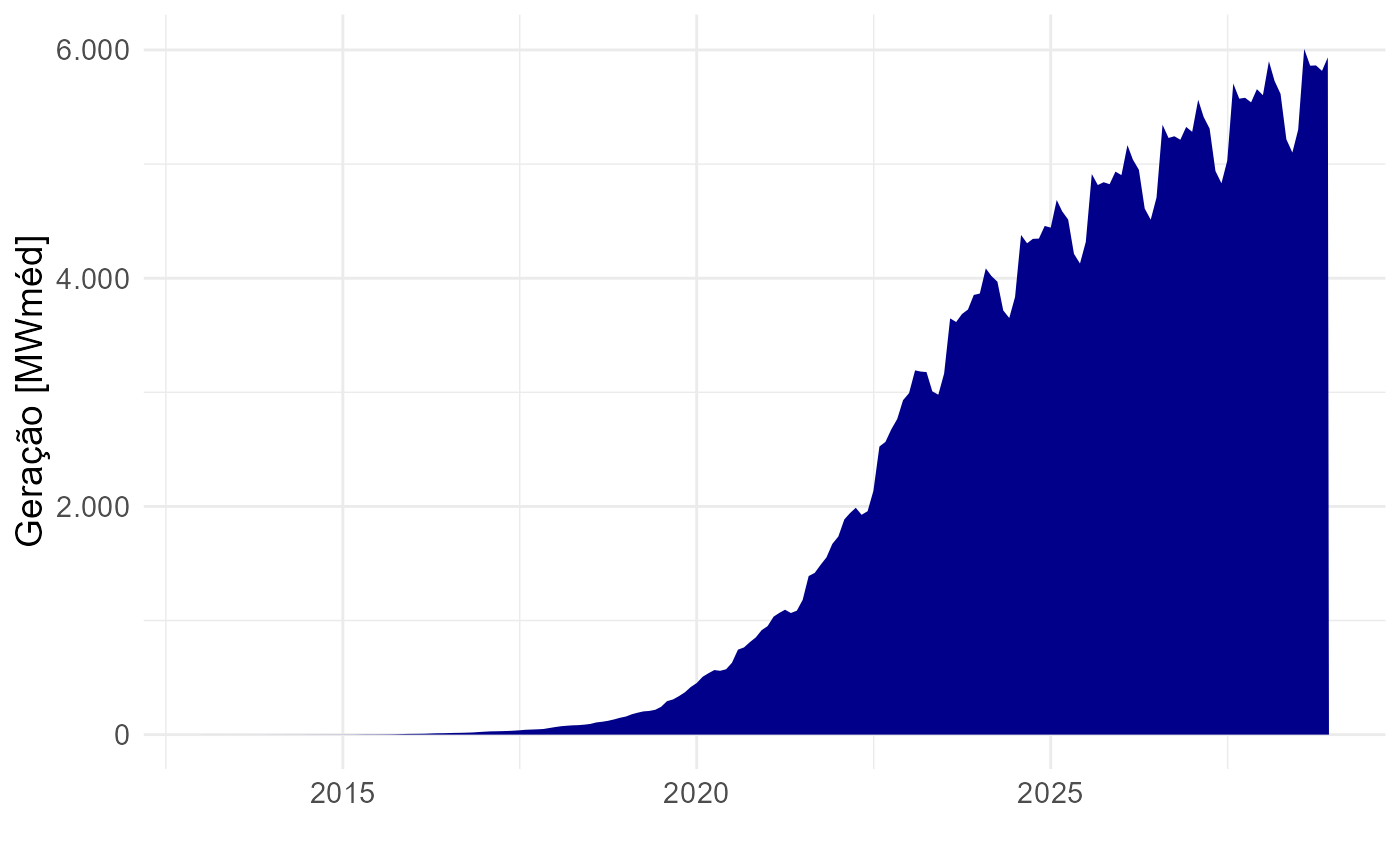
Realizando projeções por partes
Agora vamos explorar as funções intermediárias, que geram as projeções passo a passo.
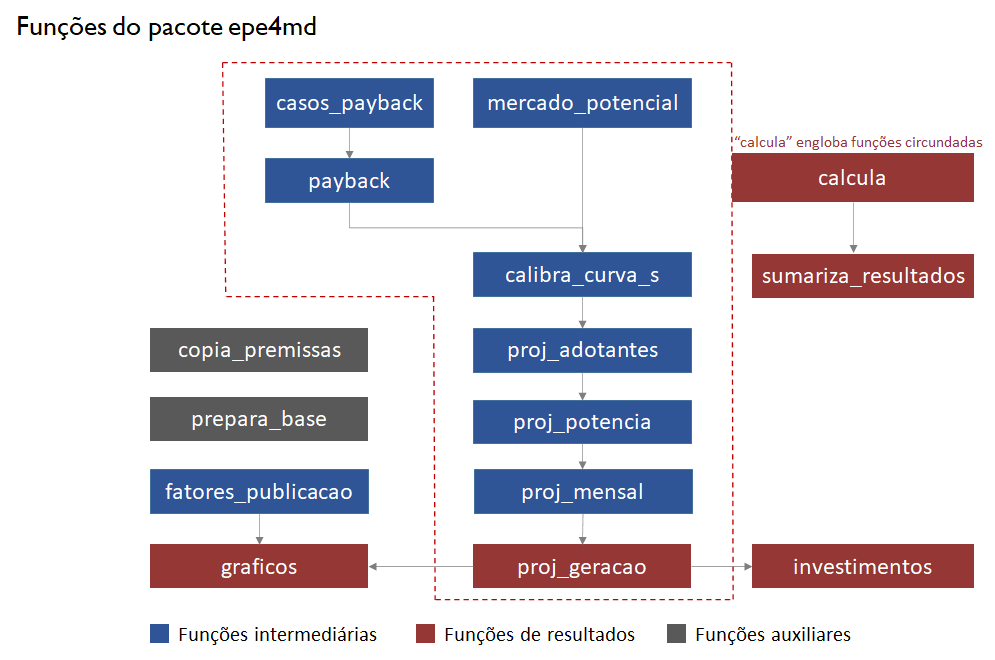
mercado_potencial
O primeiro passo é calcular o mercado potencial inicial para adotar a tecnologia. Observe os parâmetros da função. Além da definição do ano base, há os filtros residencial e comercial, que têm grande impacto no tamanho do mercado potencial, e a definição da taxa de crescimento do mercado potencial dos consumidores do Grupo A (Alta Tensão).
mercado <- epe4md_mercado_potencial(
ano_base = 2024,
filtro_renda_domicilio = "maior_3sm",
filtro_comercial = NA,
tx_cresc_grupo_a = 0)Esta função resulta um em uma lista com dois data.frames. “consumidores” possui o mercado potencial incial. “consumidores_totais” possui dados de mercado total.
consumidores <- mercado$consumidorescasos_payback
Na sequência, é necessário calcular o payback para cada caso. Para isso, primeiro é gerado um dataframe com uma lista de casos para cálculo de payback. Exemplo, 5 segmento de mercado, 54 distribuidoras, entre o ano de 2013 e 2027 (15 anos) equivalem a 4050 combinações. O dataframe gerado possui uma linha para cada caso, com os parâmetros necessários para gerar o cálculo de payback posteriormente (CAPEX, OPEX, fator de autoconsumo, ano de troca do inversor, etc.)
casos <- epe4md_casos_payback(
ano_base = 2024,
ano_max_resultado = 2028
)payback
Na sequência, é elaborado um fluxo de caixa para cada caso e são calculas as métricas financeiras de payback e TIR.
payback <- epe4md_payback(
casos_payback = casos,
premissas_reg = premissas_regulatorias,
ano_base = 2024,
altera_sistemas_existentes = TRUE,
ano_decisao_alteracao = 2023,
inflacao = 0.0375,
taxa_desconto_nominal = 0.13,
custo_reforco_rede = 200,
ano_troca_inversor = 11,
desconto_capex_local = 0,
anos_desconto = 0)calibra_curva_s
Neste passo é calculado o mercado potencial final ao unir o mercado potencial inicial com as estimativas de payback. Adicionalmente, comparando esse mercado com os dados históricos até o ano base, são estimadas as curvas S de difusão, para cada distribuidora e cada segmento.
mercado_calibrado <- epe4md_calibra_curva_s(
resultado_payback = payback,
consumidores = mercado,
ano_base = 2024,
ano_max_resultado = 2028,
p_max = 0.01,
q_max = 1
)proj_adotantes
A partir do mercado potencial e da taxa de adoção F(t), é calculado o número de adotantes anual. Também é feita a abertura de adotantes por fonte.
adotantes <- epe4md_proj_adotantes(
casos_otimizados = mercado_calibrado,
consumidores = mercado,
ano_base = 2024
)
dados_adotantes <- adotantes$proj_adotantesO resultado é uma lista com dois data.frames. “proj_adotantes” possui os resultados da projeção de adotantes de micro e minigeração distribuída. “part_adotantes” possui o resultado em termos de participação do número de adotantes frente ao total de unidades consumidoras.
proj_potencia
O número de adotantes é então multiplicado pela potência média histórica por fonte, segmento e distribuidora para se obter a estimativa da capacidade instalada.
potencia <- epe4md_proj_potencia(
lista_adotantes = adotantes,
ano_base = 2024
)
dados_potencia <- potencia$proj_potenciaproj_mensal
Nesta etapa, a projeção anual é aberta por mês.
mensal <- epe4md_proj_mensal(
lista_potencia = potencia,
ano_base = 2024,
ano_max_resultado = 2028,
ajuste_ano_corrente = TRUE,
ultimo_mes_ajuste = 2,
metodo_ajuste = "extrapola"
)O ajuste do ano corrente FALSE indica que a projeção deve começar a partir de janeiro do ano seguinte ao ano base. Caso haja um histórico mensal mais recente, após o final do ano base, ele pode ser incorporado nas projeções do ano base + 1. Para isso, deve-se escolher o método de ajuste:
O método “extrapola” irá extrapolar a potência e o número de adotantes até o final do ano base + 1 com base no verificado até o ultimo_mes_ajuste.
O método “substitui” substitui a projeção até o ultimo_mes_ajuste e mantém o restante do ano com a projeção normal. A figura a seguir ilustra esses métodos.

proj_geracao
Finalmente, esta função estima a geração de energia a partir da capacidade instalada mensal. Além da geração, o dataframe mantém os dados de adotantes e capacidade instalada.
geracao <- epe4md_proj_geracao(
proj_mensal = mensal,
ano_base = 2024
)
resumo_partes_br <- epe4md_sumariza_resultados(geracao)Comparação com função única.
geracao_funcao <- epe4md_calcula(
premissas_reg = premissas_regulatorias,
ano_base = 2024,
ano_max_resultado = 2028,
altera_sistemas_existentes = TRUE,
ano_decisao_alteracao = 2023,
ajuste_ano_corrente = TRUE,
ultimo_mes_ajuste = 2,
metodo_ajuste = "extrapola"
)
#> Warning: There were 30 warnings in `mutate()`.
#> The first warning was:
#> ℹ In argument: `saida = furrr::future_pmap(...)`.
#> Caused by warning:
#> ! There was 1 warning in `mutate()`.
#> ℹ In argument: `tir_nominal = jrvFinance::irr(fluxo_caixa$saldo_anual)`.
#> Caused by warning in `jrvFinance::irr()`:
#> ! Both Newton-Raphson and Bisection failed to find IRR/YTM
#> ℹ Run `dplyr::last_dplyr_warnings()` to see the 29 remaining warnings.
resumo_funcao_br <- epe4md_sumariza_resultados(geracao_funcao)
dplyr::all_equal(resumo_funcao_br, resumo_partes_br)
#> Warning: `all_equal()` was deprecated in dplyr 1.1.0.
#> ℹ Please use `all.equal()` instead.
#> ℹ And manually order the rows/cols as needed
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.
#> [1] TRUEO resultado igual a TRUE indica que se obteve o mesmo resultado através da projeção passo a passo e da projeção com a função completa epe4md_calcula.
Funções Auxiliares e Adicionais
epe4md_prepara_base
A função epe4md_prepara_base é utilizada para resumir a base de unidades de MMGD disponibilizadas pela ANEEL, deixando-a no padrão utilizado pelo 4MD.
Banco de Dados de MMGD da ANEEL
base_aneel <- read_csv2("empreendimento-geracao-distribuida.csv", locale = locale(encoding = "Windows-1252"))
resumo_base <- epe4md_prepara_base(base_aneel,
ano_base = 2024)Dica 1: Atente-se ao encoding. Não é raro que o csv tenha alteração no encoding. Se a leitura for feita com encoding incorreto, haverá erro ao fazer join com outras tabelas.
Dica 2: Alterações nos nomes das distribuidoras também geram erros. Nesse caso, é necessário atualizar o arquivo em “nomes_dist_powerbi.xlsx” nas premissas do modelo.
epe4md_investimentos
Esta função estima o montante de investimentos a serem realizados, a partir da projeção de capacidade.
investimentos <- epe4md_investimentos(
resultados_mensais = resultado,
ano_base = 2024)
resumo_investimentos <- investimentos %>%
group_by(ano) %>%
summarise(investimento_ano_bi = round(sum(investimento_ano_milhoes / 1000), 2))
print(resumo_investimentos)
#> # A tibble: 16 × 2
#> ano investimento_ano_bi
#> <dbl> <dbl>
#> 1 2013 0.02
#> 2 2014 0.02
#> 3 2015 0.1
#> 4 2016 0.45
#> 5 2017 0.94
#> 6 2018 2.28
#> 7 2019 7.14
#> 8 2020 12.9
#> 9 2021 21.2
#> 10 2022 37.1
#> 11 2023 28.8
#> 12 2024 27.2
#> 13 2025 11.2
#> 14 2026 14.0
#> 15 2027 12.9
#> 16 2028 11.6Gráficos
Há uma série de funções para gerar gráficos a partir dos resultados. Ver lista no site. Perceba que há parâmetros que permitem alterar a cor e tamanho da fonte dos gráficos.
epe4md_graf_pot_acum(resultado)
epe4md_graf_pot_segmento(resultado)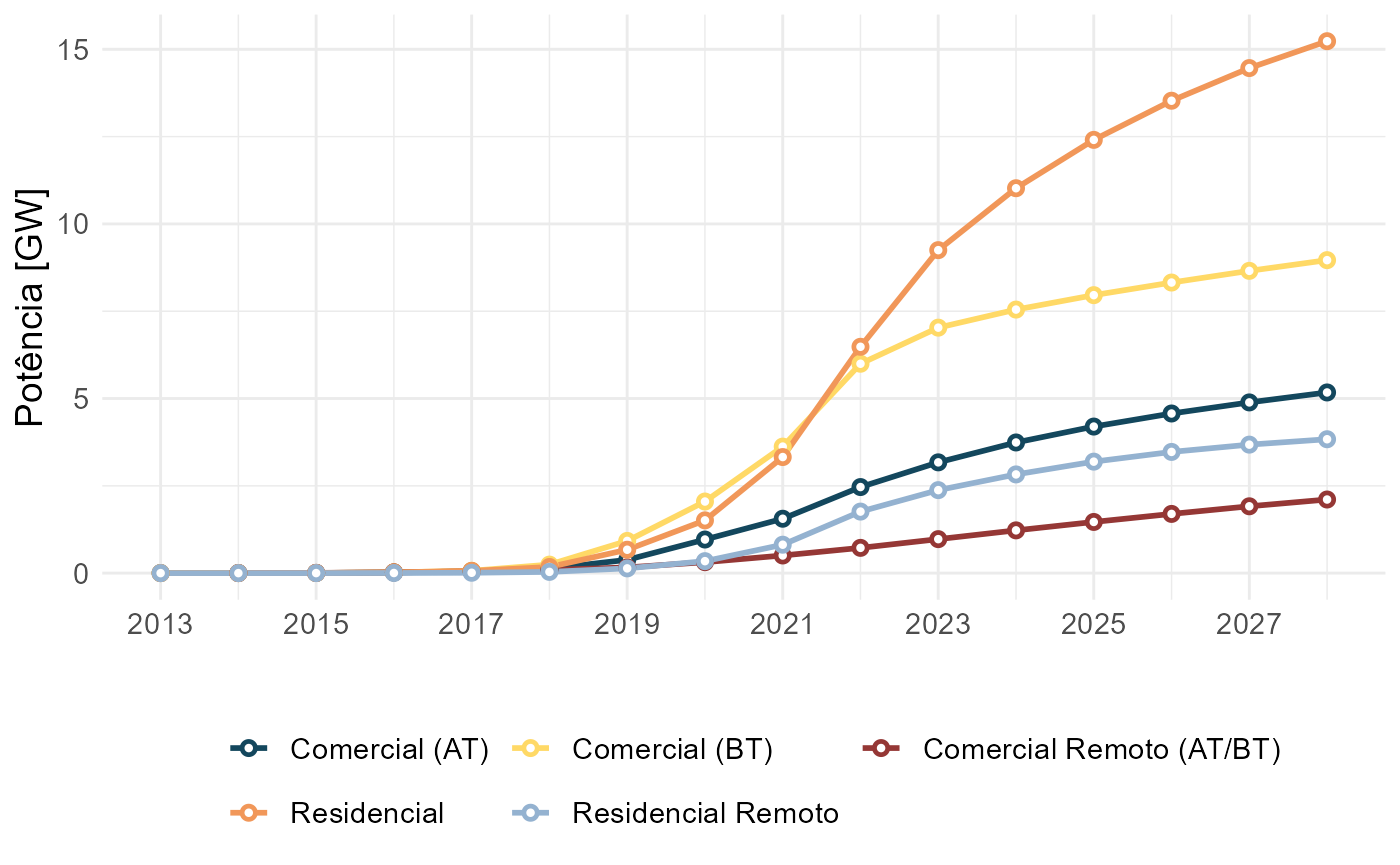
epe4md_graf_geracao_mes(resultado, cor = "#e0a96e", tamanho = 18)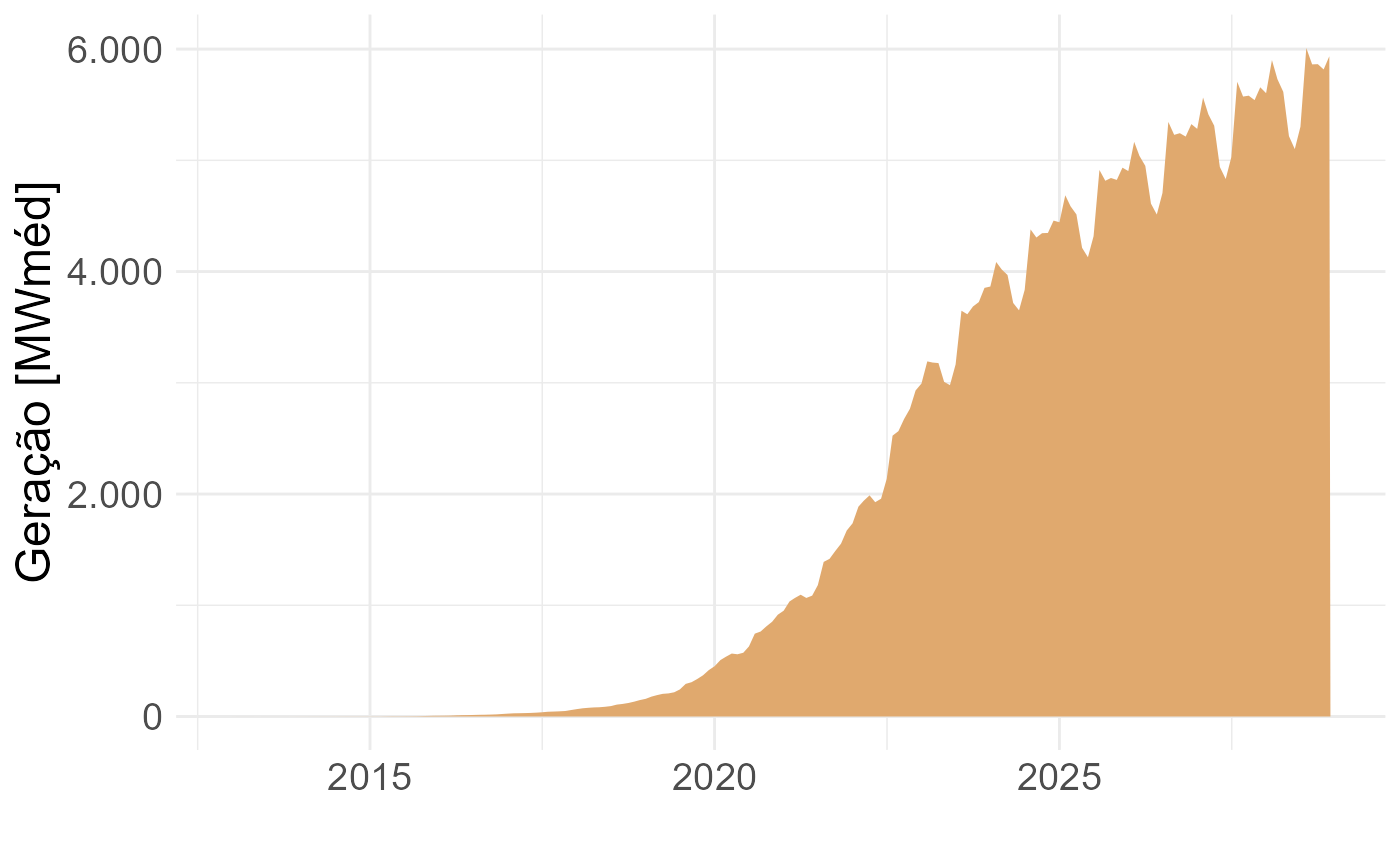
Conhecendo as planilhas de premissas
Para conhecer as planilhas utilizadas, em primeiro lugar, vamos criar uma cópia na pasta do seu projeto atual (destino default da função). Caso queira escolher um diretório diferente, o usuário pode informar através do parâmetro “destino”.
epe4md_copia_premissas(ano_base = 2024)Essa função criou na raiz do projeto atual as pastas dados_premissas/2024, com a copia de todas as planilhas de premissas.
Uma explicação breve de cada planilha pode ser encontrada no site do pacote.
Caso deseje alterar algum parâmetro, faça a alteração nas planilhas copiadas para o seu projeto. Na sequência, ao rodar as funções do pacote epe4md, informe o novo diretório através do parâmetro dir_dados_premissas, presente em todas as funções do pacote.
Vamos ver um exemplo, alterando a taxa de crescimento do mercado potencial.
Após copiar todas as planilhas para a pasta do projeto atual, aumentamos a taxa de crescimento anual para 4% a.a. a partir de 2025 e salvamos.
planilha_crescimento <- readxl::read_xlsx("dados_premissas/2024/crescimento_mercado.xlsx")
planilha_crescimento <- planilha_crescimento %>%
mutate(taxa_crescimento_mercado = ifelse(ano >= 2025,
0.04,
taxa_crescimento_mercado))
writexl::write_xlsx(planilha_crescimento, "dados/2024/crescimento_mercado.xlsx")Agora vamos fazer nova projeção, passando o caminho da nova pasta de premissas (perceba o último parâmetro).
resultado_crescimento <- epe4md_calcula(
ano_base = 2024,
premissas_reg = premissas_regulatorias,
ano_max_resultado = 2028,
dir_dados_premissas = "dados_premissas/2024"
)Portanto, há liberdade para o usuário alterar outras planilhas de premissas para gerar novos resultados.